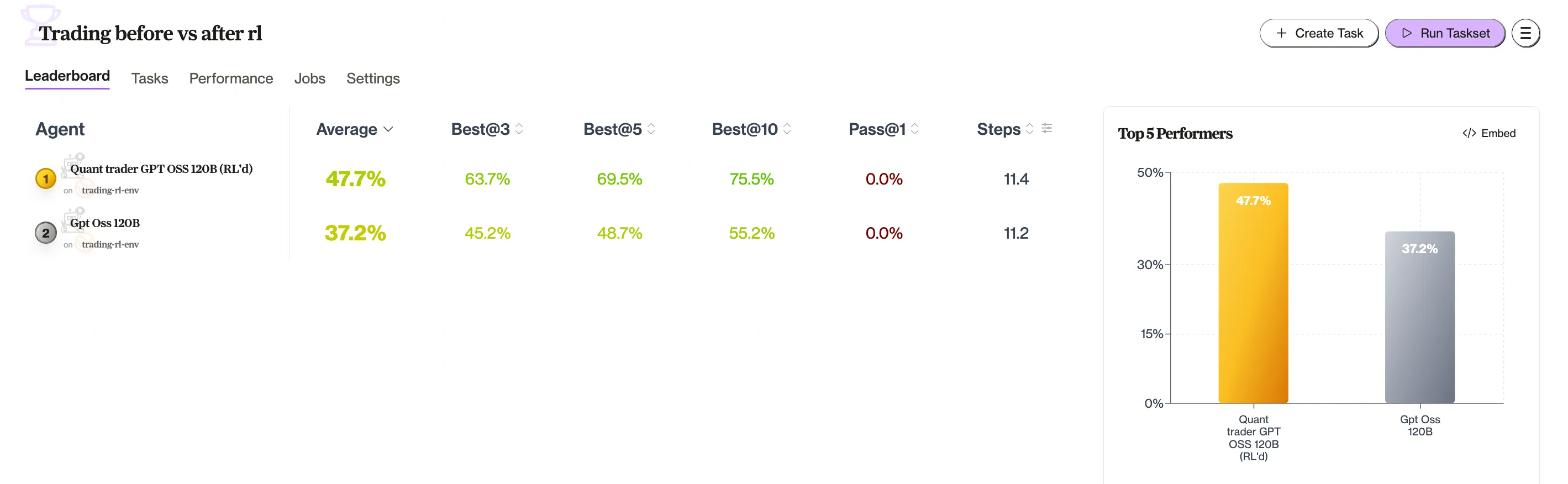
I took an open-source 120B model that scored 37.2% on a custom trading task set and ran RL post-training against a verifiable environment built on HUD. Average score rose to 47.7%. Best-of-10 jumped from 55.2% to 75.5%. Same model, no new data, no prompt changes—just a few training runs against an environment that defines what “good” looks like.
The gap these numbers close isn’t knowledge—it’s execution. Many models can describe the right workflow, then fail when asked to run it against real state: one tool call, no follow‑up checks, no completion. (In the trading environment here: place a buy, never poll fills, stop.) If you’re building agents, this is the difference between a plausible transcript and a system you can run unattended.
If you compare traces for the RL’d vs non‑RL’d model on the same eval set (leaderboard), the difference is mostly “uses the tools correctly and follows through” rather than any new kind of intelligence.
RL training targets that reliability gap by optimizing for outcome, not eloquence. You run the model inside a resettable environment, score each episode from ground‑truth state, and update the policy to increase the probability of trajectories that earn that score. When “done” is verifiable, this is a direct way to move a workflow from “works sometimes” to “works most runs” without curating new supervised data.
If you can build that environment for your own workflow, you can train against your own task set and push a base model toward higher success rate (and usually less wasted work) on the specific job you care about.
The catch: RL is brutally literal. It optimizes exactly what you specify. The core challenge isn’t the optimizer—it’s the environment contract: how you reset state, define tasks, write graders, and record traces. Environment quality is your ceiling.
TL;DR
- RL training pushed a 120B model from 37.2% to 47.7% average on a trading task set—Best@10 from 55.2% to 75.5%—in a few training runs.
- The trading domain is incidental. The same loop works for any task where success is verifiable and the environment is resettable.
- This blog walks through the full loop: environment design, graders, traces, and training—with a concrete case study in
trading-rl-env/.
The environment contract
Reinforcement learning is a feedback loop: an agent takes an action, the environment returns an observation, and a reward function assigns a scalar score. Training updates the policy to maximize expected reward over many episodes.
In agentic LLM systems, those terms map directly onto what you build:
| RL concept | What you build | Example |
|---|---|---|
| World | Runnable system that holds state | Docker image with a market simulator |
| Episode reset | Clean start, dependencies ready | portfolio.reset(initial_cash=15_000) |
| Task | What “done” means + constraints | ”Make ≥$200 net profit trading AMZ” |
| Actions / Observations | Agent tools + their outputs | place_order(), poll_fills(), market_data_snapshot() |
| Reward | Ground-truth grader | PnL from portfolio state, not from the agent’s explanation |
| Traces | Recorded action/observation sequence | Tool calls + outputs + grader breakdown |
episode start
|
v
[reset] → [task spec] → (actions ↔ observations) → [grader] → reward ∈ [0,1]
|
v
traces
If reset is leaky, tasks are underspecified, tools are awkward, or graders are gameable, RL will faithfully optimize the leak or the loophole. Environment quality is your ceiling.
The infrastructure you’d rather not build
The environment contract is the hard part. The rest is harness plumbing: build and version the container, run many isolated episodes, capture traces + grader breakdowns, compare harness changes with evals, and manage checkpoints once you start training.
In this post we use HUD for that plumbing (SDK + build/deploy + eval + traces + training), so the focus stays on environment design and the trace‑driven improvement loop—not orchestration code.
Case study: a trading RL environment
The case study environment lives in trading-rl-env/ and runs a market simulator (QuantReplay) inside a single Docker container. The HUD environment server wraps the simulator’s venue API into a small, typed tool surface and exposes trading tasks as @env.scenario(...) episodes—from take-profit-basic to constraint-heavy scenarios like maker-discipline and underwater-unwind.
Tasks and graders (sources: tasks/basic_tasks.py, tasks/quant_tasks.py):
| Scenario | Description |
|---|---|
take-profit-basic | Generate target profit on a single symbol with active trading. |
maker-discipline | Achieve steady profits with disciplined inventory control, limited drawdown, and consistent profitable round trips. |
underwater-unwind | Recover a pre-existing losing position to profit while tightly managing risk and finishing flat. |
balanced-cross-symbol | Generate diversified profits across multiple symbols with balanced per-symbol performance and controlled risk. |
small-capital-precision | Produce consistent profits with limited capital under strict risk and inventory constraints. |
quant-gauntlet-hard | Deliver high, diversified, risk-controlled performance across multiple symbols under strict execution discipline. |
The task boundary: what the agent sees vs what the grader sees
The take-profit-basic scenario (source: tasks/basic_tasks.py) is the episode boundary: reset to a known baseline, yield a spec the agent sees, then yield a scalar reward the agent never sees.
@env.scenario("take-profit-basic")
async def take_profit_basic(symbol="AMZ", initial_cash=15_000.0, target_profit=200.0):
portfolio.reset(initial_cash=initial_cash)
_ = yield f"""You are a trader on XETRA. Starting cash: ${initial_cash:,.0f}.
Goal: make at least ${target_profit:,.0f} net profit trading {symbol}.
Your score is based on your portfolio state (not explanations)."""
grade = Grade.from_subscores([
PnLGrader.grade(weight=0.80, portfolio=portfolio, # ← ground truth
initial_cash=initial_cash, target_profit=target_profit),
TradeActivityGrader.grade(weight=0.20, portfolio=portfolio), # ← shaping signal
])
yield grade.score # ← optimizer sees this
Because the scenario is a generator, grading doesn’t run until the agent is done. The agent can’t see how it’s being scored, which reduces the incentive to game the grading mechanism instead of the task.
Why the activity grader exists
Without a shaping signal, “did nothing” and “tried and failed” both score 0.0—the optimizer can’t distinguish them, and early training collapses into indistinguishable zero-reward episodes. The 80/20 weighting means the shaping signal is strong enough to differentiate early episodes but never dominates the primary objective.
Important lines from the graders (scoring logic only, from grading/graders.py):
#https://github.com/vrn21/trading-rl-env/blob/main/grading/graders.py
pnl = _clamp(float(portfolio.net_profit()) / target_profit) if target_profit > 0 else 0.0
fills = portfolio.fills
buys = any(str(f.get("side", "")).upper() == "BUY" for f in fills)
sells = any(str(f.get("side", "")).upper() == "SELL" for f in fills)
activity = 1.0 if (buys and sells) else (0.5 if fills else 0.0)
reward = 0.80 * pnl + 0.20 * activity
Narrow tools prevent reward hacking
The action surface is deliberately small and typed—no shell, no DB access, no simulator internals: tools/
| Category | Tools |
|---|---|
| Market observation | list_symbols, market_data_snapshot, get_last_price, get_listing_rules |
| Order management | place_order, replace_order, cancel_order, poll_fills |
| State inspection | get_portfolio |
Keeping “reward-hacking by side-channel” out of the action space means the agent can only improve its score by actually trading better.
Boot sequence: keep stdout clean for JSON-RPC
The container runs Postgres, QuantReplay, and the HUD MCP server in a single process tree. In run.sh, the critical trick is fd redirection—every service’s output goes to stderr so stdout stays clean for the JSON-RPC protocol:
exec 3>&1 # save stdout to fd 3
exec 1>&2 # redirect all output to stderr
# ... start Postgres, wait for ready ...
# ... start QuantReplay server, wait for ready ...
exec 1>&3 # restore stdout for MCP server
exec 3>&-
exec hud dev env:env --stdio
Without this, any stray log line from Postgres or QuantReplay corrupts the MCP stream and the agent sees garbage observations.
Build your own environment (the shortest path)
The simplest useful environment has three things: a tool, a task that defines “done”, and a ground-truth score. Minimal example: hud-blank/env.py. Also there are other templates like: coding-template, hud-browser
① Tool — the action surface:
@env.tool()
async def act() -> str:
resp = await http_client.post("/act") # ← mutate world state
return f"Counter: {resp.json().get('count', 0)}" # ← observation back to agent
② Scenario — the task boundary (prompt now, grade later):
@env.scenario("count-to")
async def count_to(target: int = 10):
await http_client.post("/reset") # ← clean episode start
_ = yield f"Call act() until the counter reaches {target}." # ← agent sees this
current = (await http_client.get("/state")).json().get("count", 0)
yield min(1.0, current / target) if target > 0 else 1.0 # ← optimizer sees this
③ Initialize — a fail-fast readiness gate:
@env.initialize
async def init() -> None:
(await http_client.get("/health")).raise_for_status()
Verify end-to-end (from hud-blank/):
hud build .
uvicorn backend.app:app --port 8005
python local_test.py
=== Test 1: Standalone Tools ===
Tools: ['act']
Counter: 1
Counter: 2
Counter: 3
Deploy, eval, trace, train
Build and deploy
From an environment directory (example: trading-rl-env/):
hud build . # local smoke test
hud deploy . # remote build + versioning
Or connect a GitHub repo in the HUD dashboard—each push triggers a build and produces a versioned environment artifact.
Traces as your debugger
Start with a small task-set run and inspect traces in the UI: hud.ai/evalsets/my.
You can also initiate the same run from the CLI (task set JSON: remote_tasks.json):
hud eval ./remote_tasks.json --model <model_id> --remote
An environment is “ready” only when you can explain both failures and successes from traces. Concretely, check for:
- Reward hacking: high score without accomplishing the real objective.
- Task ambiguity: multiple reasonable interpretations, only one matches the grader.
- Leaky reset: success depends on leftover state from prior runs.
- Tool/constraint mismatch: tools make it easy to do the wrong thing (or impossible to do the right thing).
- Brittle graders: checking an intermediate artifact instead of final state.
Train only after the contract stops moving
- Fork a base model — pick a trainable model and fork it so you own a versioned checkpoint.
- Train — select your environment version + task set, set run limits (episode count, max tool calls, timeouts).
- Eval gates — run an eval set between training runs to catch regressions early.
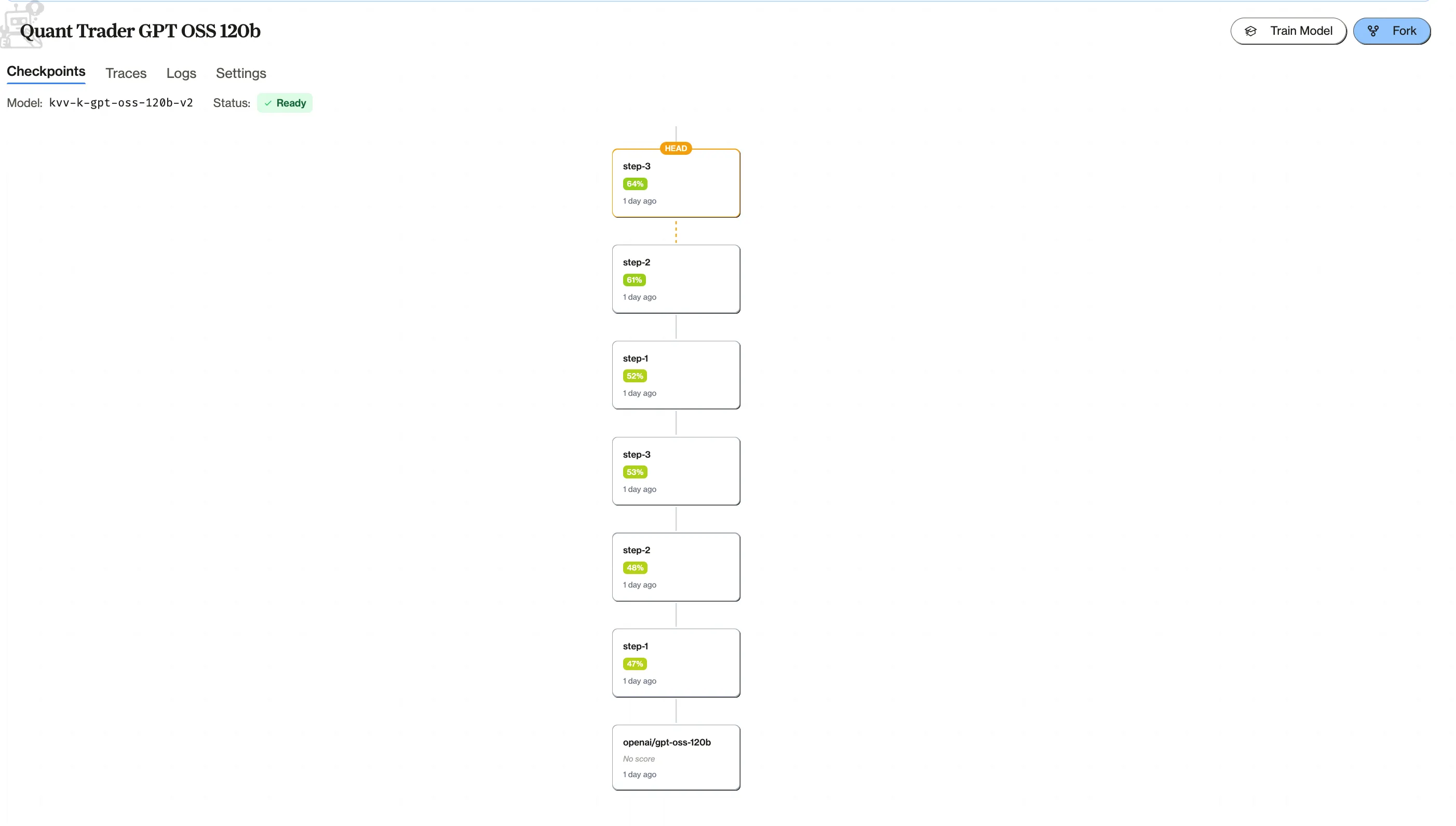
This model in the case study is forked from GPT OSS 120B and trained for 6 RL runs on the same trading task set (eval set).
Treat each result as a new checkpoint. Compare against the previous one on the same evals, inspect traces, keep the better head. If a run regresses or reward-hacks, fix tasks/graders/reset and rerun instead of stacking more training.
RL trained models can be directly interacted with HUD’s sdk/apis
from hud.agents import OpenAIChatAgent
agent = OpenAIChatAgent.create(model="<your-forked-model-id>")
Best practices
Most RL failures aren’t “RL”—they’re environment bugs. These are the practices that actually move outcomes:
- Match real usage, control the rest: same APIs, state transitions, and workflow constraints as production—but stub what you can’t control (mock external services, replay recorded responses, keep data local).
- Deterministic reset: each episode must start clean and repeatably. If resets aren’t reproducible, your reward signal becomes noise.
- Tasks are specs, not prompts: define “done” clearly, include constraints, and parameterize difficulty so you train on a distribution—not one handcrafted case.
- Grade from ground truth: tests, DB state, simulator truth, logs. Add invariants and secondary signals to close obvious loopholes (Faulty reward functions, Concrete Problems in AI Safety).
- Keep tools boring and typed: narrow schemas, structured returns, explicit error modes, sensible limits so “exploration” can’t become “break the system.”
- Trace everything you need to explain a score: tool calls, tool outputs, key state snapshots, grader breakdown. If you can’t explain failures and successes from traces, iterate on the contract before you scale training.
Conclusion
If you have a model that needs to get reliably good at a specific workflow, RL on custom, verifiable tasks is one of the cleanest post-training paths to get there.
The loop: build a resettable environment, write clear tasks, grade from ground truth, iterate with traces until the contract is trustworthy, then train and validate a checkpoint you can actually deploy.
If you still have questions, feel free to contact me hello@vrn21.com